
“Latest Google News!”
10/7/04 – Google’s PR (Page Rank) update
10/6/04 – “Google Growing – An Update On Google” 
Google Browser – Playing Ruthless with Redmond – Google is most likely developing an web browser of its own to compete with Microsoft’s Internet Explorer. This will allow Google to “brand” a user’s experience, much like Microsoft does today. (Look at the top of your browser. About 90% of you will see the words “Microsoft Internet Explorer”) Google has recently introduced its own Email system known Gmail and offers a host of other features that could be incorporated into a browser. The development of a Google web browser is much like Microsoft developing its own search engine. It is a direct challenge to a major rival and a smart move leading up to the next major phase of the search engine war, expected next spring. Here’s the background on the browser story.
Google has a great deal invested in its engineering staff. Their resumé filtering process for engineers is the stuff of legends and is designed to allow only the brightest to solve their way through a series of mathematical puzzles. Joining those who solved the puzzles are a number of notable new staff members personally headhunted and recruited from other tech firms. According to a report in Digital Media Europe, Google has hired Java pioneer Joshua Block away from Sun Microsystems, Adam Bosworth and four others from Microsoft’s Internet Explorer development team, and in a major coup, one of Microsoft’s lead developers on the Longhorn OS, Joe Beda. This sudden grouping of famous IT engineers, combined with Google’s April 2004 registration of the domain name “gbrowser.com” gives a great deal of credibility to the rumour. Google has also dedicated a substantial amount of time, attention and money to the Mozilla community. Mozilla is an open-source browser. Open-source software allows developers to work with the software-code to improve or change the product. By offering resources to Mozilla developers, Google may be micro-funding the creation of what becomes the backbone of a Google-branded browser. Google users would likely accept and use a Google browser, especially if it is based on the current tech favourite, Mozilla. Once they have converted from IE to Google’s product, directing their interest will be as easy as tracking their movements, two important components in making the bottom line.
Money as a Necessary Evil – Expanding Revenue Sources – Making money is an important part of running a successful business. One might think that becoming the world’s most referenced information source would be enough to make money. Apparently it’s not. Moving the most advertising on the web… now that’s a ticket to making good money. Google pushes product like nobody’s business. With over ½ of all searches conducted through Google’s system in one way or another, and the largest contextual advertising distribution network on the planet, Google’s only major competition is Yahoo/Overture. Unlike Yahoo/Overture however, Google is in a somewhat precarious position regarding revenues. Over 90% of Google’s quarterly revenues is said to come from contextual advertising. That’s a lot of eggs to put in one basket, no matter how large that basket may be. The contextual advertising market is changing and this is a cause for concern for all search tools dependent on advertising revenues. Google is betting the server-farm on advertising so it has to develop as many ways as possible to deliver that advertising to viewers and do it in such a way that advertisers benefit more than they would working with Yahoo. Google has thus far been successful in competing with Yahoo’s Overture. They have developed a better distribution system, have more advertisers, and have better semantic contextualization abilities than Yahoo. What they don’t have is other major revenue sources.
One of the goals of all search engines is to deliver the most relevant results possible to each individual user. Concepts such as personalization and localization of search results are based on this goal. One of the effects of localization and personalization will be the adoption of Google as a replacement for daily-use items such as the phone book and yellow pages. This is an obvious goal for Google and other search tools however it also represents an extraordinary and recurring revenue generator, especially as the Pay-per-Call model layers over the current Pay-per-Click model. As Google engineers find new ways of presenting search to the public, perhaps we’ll see new kitchen appliances referencing Google for recipes or even Froogle for the lowest prices on local produce. Eventually, digital radio and television will become the standard. Wouldn’t it be cool to look for a specific song or show currently playing somewhere? That may sound far-fetched today but, if they can do it with the news, they’ll soon do it with other digitalized signals. The bottom line to this section is the bottom line. Google knows it needs to diversify its revenue streams if only to continue to satisfy investors.
8/31/04 – Google’s major update
7/26/04 – “Let’s (Google) Dance!”
The last Google dance (to the best of my knowledge) was on or about the 22 of June this year. Here is a list of approximate dates for the past few dances;
August 31, 2004
July 26, 2004
June 22, 2004
June 1, 2004
April 22, 2004
April 07, 2004
March 19, 2004
February 11, 2004
January 26, 2004
January 11, 2004
December 23, 2003
December 6, 2003
November 20, 2003
|
|
|
3/14/04 – “In Google We Trust” 
With an estimated 200 million searches logged daily, the Web site that has become a verb has gained a near-religious quality in the minds of many users.Ben Silverman is what you might call a Google obsessive. A producer and a former talent agent best known for bringing Who Wants to Be a Millionaire to US television, Silverman Googles people he is lunching with. He Googles for breaking news, restaurant reviews and obscure song lyrics. He Googles prospective reality-show contestants to make sure they don’t have naked pictures floating around the Web. And, like every self-respecting Hollywood player, he Googles himself. Competitively.
It’s more like the new kabbalah. With an estimated 200 million searches logged daily, Google, the most popular Internet search engine, “has a near-religious quality in the minds of many users,” said Joseph Janes, an associate professor at the University of Washington in Seattle who taught a graduate seminar on Google this semester.
“A few years ago, you would have talked to a trusted friend about arthritis or where to send your kids to college or where to go on vacation. Now we turn to Google,” he said.
For the entire article, go here!
|
|
|
3/12/04 – Awesome Google & Yahoo Results Comparison Tool!
For example, on a “cars” search, why does lotuscars.com, #3 in Google, appear at #41 in Yahoo? The #5 spot in Yahoo, http://cartalk.cars.com ranks at #41 in Google. What’s going on here? On “alligator,” a less competitive search term, there are 40 exact matches, while for cars there are only 32.What does this mean? Probably nothing, but for those who are looking to build their annecdotal theories of the difference between the algorithms, this tool will get you off to a great start.
|
|
|
2/04/04 – “Is Google Web Search at Risk?” From 
… According to search engine experts, American Blind will find it more difficult to prove infringement by Google in its regular search listings. Those listings are, in a sense, based on Google’s editorial judgment embodied in its algorithms and technology, something one might argue is covered by First Amendment protections, said Danny Sullivan, editor of search industry site SearchEngineWatch.com.
… Google has tried to avoid conflict with trademark holders, often barring competitors from bidding on keywords that match unique trademarks, as it has done for companies such as eBay Inc. and Dell Inc., Sullivan said. But conflict has become almost inevitable with descriptive terms, especially as search companies such as Google earn growing profits from search-based advertising.
“Anytime you bid on a word and understand that it’s a trademark…you better feel confident that if you go to court you can defend the reasons for doing that,” Sullivan said.
For the entire article, Click Here!
|
|
|
1/24-26/04 – Latest Google-Dance
|
|
|
1/15/04 – “Google Rumors” From
Rumor 3: Google is using “Bayesian Spam Filters” – There is no conceivable way Google could implement a “Bayesian” filter to recognize “search engine spam,” and I can’t believe that hundreds of very intelligent engineers would attempt to do so. Google isn’t trying to “penalize” or “filter out” anything. The people at Google are trying to build a system that identifies the most relevant web pages. Where they use filtering, it’s to avoid being tricked by hidden text and that sort of thing. Bayesian filtering is very different.
Rumor 4: Google is punishing reciprocal links – The theory here is that Google is punishing web sites that trade links with other web sites. Maybe, if that’s all you do, but that’s probably been the case for some time.
Rumor 5: Google is punishing “optimized” pages – The rumor here is that Google is trying to drop “optimized” pages. Not only does this not hold up under close scrutiny, it doesn’t make any sense to begin with. Another way to describe an “optimized” web page would be “a well structured page that clearly indicates the relevant topics.” Does Google penalize dirty tricks like hidden text, over-stuffing HTML tags, etc.? Of course they do, but that’s not optimizing, folks, that’s spamming. Penalties for spamming are nothing new.
Rumor 6: Google is punishing “link text” – Nope, not true. If it were possible to create a penalty for another site by linking to them with the wrong words, you’d have complete chaos in a very short time.
Rumor 7: Google Is Out To Get You, And It’s Personal – I haven’t done a whole lot of detailed research to substantiate my beliefs on this, but trust me, it’s not personal. The search engines are all trying to deliver quality search results, and maybe you aren’t giving them what they’re looking for. That doesn’t mean you don’t have a good web site. It doesn’t make you a bad person. Maybe you just need to do some things differently.
For the entire article, go here!
|
|
|
12/30/03 – “How To Optimize Your Google Description” From
Where is Google pulling the snippet description? – Currently Google is pulling the snippet from any one or combination of the following areas:
2. First ALT text found on the page.
3. First text found on the page (which may be a heading tag, body text, etc.).
4. Additional heading tags on the page.
5. Additional body text found on the page.
6. Additional ALT text on the page.
7. Navigation bar on the left-hand side of the page (which is rarely a relevant description of a site!).
8. Copyright information at the bottom of the page.
9. Wherever the keyword phrase is found.
If you don’t like the description, try modifying the area where Google is pulling the description, and see if Google will pick up the changes and use the new description as the snippet in the search results.
Why? …because your description plays a crucial click factor! – Remember that the description of a page is crucial when it comes to increasing click throughs to your site. If your description is compelling and designed to produce clicks, you may even get more traffic than a competitor who is ranked higher.
To a greater degree than most are aware, you can manage some control over your Google descriptions. This is clearly a case where a little research and some easy tinkering can make a big difference in how your site is presented to potential customers, thereby increasing your click-through traffic coming from Google.
For the full article, go HERE!
|
|
|
12/24/03 – “Top 10 Google Myths Revealed” From 
Myth #3: PageRank is a Value Based on the Number of Incoming Links to Your Site – This myth is a frequent source of incorrect assumptions about Google. People will often see that a site with fewer incoming links than their own site has a higher PageRank, and assume that PageRank is not based on incoming links. The fact is that PageRank is based on incoming links, but not just on the number of them. Instead PageRank is based on the value of your incoming links.
Myth #4: Searching for Incoming Links on Google Using “link:” will Show you all Your Backwards Links – Similar to Myth #3, people will sometimes look for backwards links to a site on Google and fine none, but if the site does have a PR listed and it is in Google’s cache, they know that the toolbar isn’t just guessing. The reason for this is that Google does not list all the links that it knows about, only those that contribute above a certain amount of PageRank.
Myth #5: Being Listed in the Open Directory Project Gives you a Special PageRank Bonus – Google uses Open Directory Project (DMOZ.org), to power its directory. Coupling that fact with the observation that sites listed in DMOZ often get decent and inexplicable PageRank boosts, has lead many to conclude that Google gives a special bonus to sites listed in DMOZ. This is simply not true.
Myth #6: Being Listed in Yahoo! Gives you a Special PageRank Bonus – This myth evolved much in the same was as Myth #5. Google has been partnered with Yahoo! for a number of years by providing secondary search results, and just recently (Fall, 2002), Yahoo! started using Google to provide primary search results. Because Yahoo! uses Google, many have assumed that Google also uses Yahoo!, which is not the case. The only PageRank you will gain from being listed in Yahoo! is the same as the PR you’d gain from any other site of equivalent weight.
Myth #7: Google Uses Meta Tags to Rank Your Site – This myth is left over from the days when most search engines used meta tags. However, Google has never used them. This fact may be contested by some people, so I wouldn’t post it without proof.
Myth #8: Google Will Not Index Dynamic Pages – Some search engines have, in the past, had problems with dynamic pages, that is, pages that use a query string. This was not due to any technical limitation, but rather, because search engines knew that it was possible to create a set of an infinite amount of dynamic pages, or they could create an endless loop. In either case, the search engines did not want their crawlers to be caught spidering endless numbers of dynamically generated pages. Google is a newer search engine, and has never had a problem with query strings. However, some dynamic pages can still throw Google for a loop.
Myth #9: Google Will Not List Your Site, or Penalize it, if you use Popups – This is a relatively minor myth but it still pops up (pun intended) every once in a while. Google has an advertising program called Adwords, and one of their policies is that they do not allow sites that use popup windows to participate in this program.
Myth #10: Google will Penalize you if You’re Linked to by a Link Farm – Google has policies against the use of artificial means to increase your PageRank, which specifically include things like joining a link farm. Even so, Google can punish you if you link to a linkfarm from your site, or otherwise put hidden links in your pages. So the simple truth is that you can be punished for what you do to your own site, but not for getting linked by another site.
For the full article, go HERE!
|
|
|
12/15/03 – “Danny Sullivan Explains Google Penalties From http://webproworld.com
Danny says… Danny Sullivan is editor of http://SearchEngineWatch.com and also organized and moderated the Search Engine Strategies Conference. I asked his opinion on Marissa’s comment regarding what readers should do if their sites drop significantly on Google.
“I saw that headline summary in SearchEngineGuide, if I remember correctly, and I noticed that it freaked some people out,” Danny replied. “I remember [Marissa] saying that because it sounded really significant, but I took Marissa’s comment slightly different. I think what she probably meant was not that who’s linking to you can hurt you – the reason why is because it’s very easy for you to hurt your competitors. That’s why it’s a terrible thing to use for relevancy. What I do think happened is [Google is] looking at links in a different fashion. If you’ve been in a neighborhood that’s been helping you previously, [it] might not be helping you now.”
Danny says that doesn’t necessarily mean Google is penalizing you for inbound links. It just means that those links aren’t counting as much towards your Google ranking.
Is Google getting smarter? Don’t be surprised if you notice Google getting smarter about links. “In the past, every single link was counted for something,” Danny says. “Perhaps now Google’s still looking at the links but not counting them as much. They’re perhaps not giving you as much credit as they used to.”
Won’t You Be My Google Neighbor? Danny believes Marissa’s comment was misinterpreted, and he thinks there’s another question at hand here. “I guess it comes back to: does the community have more of an influence now than in the past? I suppose so. On one hand, yes, but on the other hand, Google may simply be redefining how it determines a community and what that community is worth. [Google] has always looked at who’s linking to you… I think it’s still doing that, but it’s using a different scoring method…”
So was it all just a misunderstanding? Danny thinks so. “I honestly don’t think she’s lying,” he says, noting that Marissa is a very credible representative of Google. “Marissa is a wonderful resource. She’s really, really good, but she doesn’t deal with the webmaster side as much.”
Danny believes that Marissa knows what she’s talking about but perhaps she didn’t choose her words correctly.
What did she mean, then?
“I think what she probably meant was that who links to you counts, and yes, that’s always been the case, but who links to you doesn’t count as much as it did in the past.”
Who Gets Penalized? Is the penalty completely out of the question? Probably not. “If Google were penalizing sites for getting links, then that is a significant repercussion,” Danny says. “I have no doubt that in some cases [Google] might penalize, but the criteria would be really high.” Danny could understand a site getting penalized “if you’re running fifty websites that have no reason to exist other than linking to themselves or if [Google] sees other stuff that makes them think, ‘These links are odd! Not only should we not count these links, but we should do something to this website, period!’”
”It’s too easy to make mistakes.” But as far as the everyday link exchange, that’s innocent enough in his eyes. When it comes to link exchanges, “it’s too easy to make mistakes,” Danny says. And he believes the people who run Google understand that. After all, they are only human!
|
|
|
11/19/03 Google-Dance Shakes Things in the SEO World
Important: It’s critical for you to understand that our research is still very preliminary (in the testing phase) and Google, indeed, is still fiddling with this algorithm. They could even change it drastically again at any time. There is no stability in what is going on and, until such stability returns at Google, what we are advising you to do may, or may not, work tomorrow. However here’s what we are doing and our strategy is producing good results (so far). But, still, we can only hope that it continues to work and produces favorable results for you as well.
|
|
|
9/19/03 Microsoft Goes after Google! From ![]()
|
|
|
|
|
|
9/5/03 Google Update Pattern From ![]()
- Incremental ranking movements were observed about every 4-5 days. These observations were most prominent in campaigns that were young and had ongoing link optimization efforts. Perhaps Google was incrementally attributing partial value from newly crawled links.
- Large ranking movements took place within a 25-30 day period. Google backlink counts changed within 5-7 days following.
- Different websites seem to be receiving their large ranking movements at different times. Although difficult to tell, there appears to be evidence to support an Alpha sort order (e.g. URLs starting with the letter B receive large ranking movements just prior to URLs starting with the letter C). Since this observation only applied to young campaigns where large movements could be observed, the sample set was small and was not statistically significant (a fancy way of saying it could be coincidence).
|
|
|
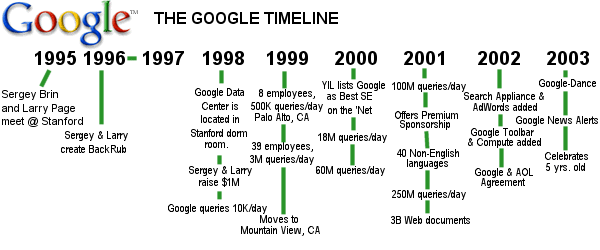
8/26/03 – Google Celebrates 5 yrs. old – “The Search Engine that Could” from USAToday.com
Today, millions Google themselves, friends, blind dates, employers and employees. Students wait till the last minute to Google assignments. Shoppers Google products and prices before purchasing. One columnist suggested that Google is so vital in our lives that it’s a deity of sorts, everywhere and all-knowing. As Google prepares to celebrate its fifth anniversary Sept. 7, it’s expanding beyond basic searches. Google now embraces comparison shopping, news, the personal online journals called Weblogs and even a service that blocks pesky pop-up ads. It answers 200 million search requests a day — more than 2,300 every second — in 88 languages. It indexes 3.1 billion Web pages with the help of 10,000 supercomputers.
The aim: to organize the world’s information. “We’ve been very lucky,” says Page, 30, wearing black Google-logo T-shirt and jeans during an interview at the Googleplex, where bicycles, Segways and hammocks line the hallways and the Grateful Dead’s former chef oversees the 24-hour food operation. “We’ve made a tremendous amount of progress, but we have so much more we can do.” Google at 5 “is beyond anything I would have pondered extrapolating,” says Brin, 30. “The most amazing thing is seeing how important search is to people in all walks of life.”
Take, for example, Havva Eisenbaum. She Googles people “every day” — friends she went to school with, old boyfriends, new clients, buddies she meets via instant messages. “I don’t know what I’d do without it,” says Eisenbaum, 25, who works at a Hollywood talent agency and as an SAT tutor. When she books new students, she looks up their parents first. “I want to make sure they’re not crazy,” she says. “I always find stuff, too.” When users type in names or subjects at www.google.com, results pop up in seconds: a list of links to Web sites and discussion boards on which the name or subject are mentioned.
With the Web at 6 billion pages and growing, organizing the chaos is an increasingly daunting task. Yahoo was the first major enterprise to tame the Net with a highly regarded directory of Web sites vetted by a team of editors. But to cover the larger Web, Yahoo had to look to outside sources for software that “crawled” Web pages and indexed them by keywords. Savvy Webmasters found ways to exploit Web crawlers by sticking multiple keywords into the background language of pages. Search results often were skewed. Steven Johnson, who writes for Slate.com, says the link system is skewed because Web users who create many pages and generate many links, such as Webloggers, tend to rise to the top of the list. Google “reflects the biases of the overall Web population,” he says.
Google staffers concede its mechanisms aren’t perfect. “We’ve come a long way, but we believe search is in its infancy,” says Marissa Mayer, Google’s director of consumer products. “We need more content and ways to interact with search. For instance, you can’t ask a question and have it answer you.” Google bases its results on popularity, judging pages by the links to them from other sites. The larger the links (influential sites that get lots of traffic), the higher the page is listed among results. Google (named for the “googol,” the mathematical term for 1 followed by 100 zeros) calls this the PageRank — named after Page. The technology not only proved far more effective in delivering pertinent results, but it also was lightning fast. A search for a popular topic such as the California recall election retrieves more than 1 million links in a fifth of a second.
The system was born when Brin, a Russian émigré, met Page when both were PhD candidates at Stanford. He and Page, the son of a computer science professor at Michigan State University, decided to merge their graduate projects on search technology. The two knew they had something when 10,000 fellow students and professors started using it regularly. Stanford still owns a small piece of Google, which stands to be worth a fortune if Google goes public as expected next year. Google always has explained its success by its singular focus. “We never strayed from search,” Page says. But the horizons of those searches have been broadening in the past year or so, including:
- A test comparison shopping site, Froogle (froogle.google.com). On the regular Google, Wojcicki says, “if you type in china, you’ll more likely get the country than the dish. This is a way around that.”
- A test news site that assembles and categorizes reports from more than 4,000 sources worldwide (news.google.com).
- The purchase of Blogger, a site for the increasingly popular Weblogs. Page says blogs fall in line with Google’s pursuit of information. “If you search a plane crash, we’ll give you a site about the plane and news articles about what happened. Now we can also bring you to personal Web pages to tell you how people feel about it.”
Everett Ward, assistant director of the Salt Lake City library, says the danger in researchers relying so much on Google and online information is that much of it is unsourced and inaccurate. “One of the problems with online searching is trying to understand the credibility and authority of what they’re looking at. Google sends you everything. People still come to the library to research, not because they can’t find it online, but they’re finding too much.” In her fifth-grade classroom in Atlanta, Amy Wilson worries that Google “doesn’t teach (students) the basic skills they need, because they’re getting quicker access in a shorter amount of time. They hardly go to the library or encyclopedia anymore.” Page says he wants people to still frequent libraries, even if it is “a lot easier to go to Google first.”Google is well compensated for its success. Analysts estimate Google’s revenue at $600 million to $800 million this year from advertising and licensing fees. Small sponsored links are served to surfers along with search results, and many Web sites pay to let users search their domains via Google. Though the founders don’t have to put in the time, they still work long Silicon Valley hours. Wojcicki says that even with their newfound wealth, Brin and Page are fabulously eccentric. “Sergey’s car broke down recently, and instead of getting it fixed, he either bummed a ride home with other employees or rollerbladed to work.” Page says his only extravagances have been boy toys, including a high-definition video camcorder and a $2,000 digital camera.
Meanwhile, Google already has outgrown the Googleplex and plans to move to a bigger facility. And more competition looms: Yahoo this year purchased search engine Inktomi, which provides searches for Microsoft’s MSN, and Overture, Google’s main rival in paid search marketing. MSN also says it will upgrade its own service to reduce reliance on outside providers. Yahoo hasn’t commented on its future with Google. Page’s response to the competition is quietly confident: “Search is going to get a lot more interesting. And that’s all to the good. We’re a society that’s used to losing information to new generations. Now more than ever, search is really important.”
|
|
|
8/14/03 – Google-Dance has ended
|
|
|
8/9/03 – Google-Dance has begun
|
|
|
8/7/03 –
|

|
|
|
8/4/03 – ![]() Targeted by Search Engine Rivals From
Targeted by Search Engine Rivals From ![]()
…
HOW GOOGLE WORKS – Google’s technology is built around a secret formula called “PageRank” that rates the relevance of Web sites based on the number of links from other relevant Web sites. The method has raised concerns that Google has created a caste system in which a group of elite Web sites largely determine the popularity of other sites. But Web surfers have embraced the approach. “Googling” information has become so popular that Google.com attracts some of the heaviest traffic on the Web. Only Microsoft’s MSN.com, AOL and Yahoo lure more visitors in the United States.
Read the entire USATODAY article here!
|
|
|
7/10/03 – The Truth About Google – “What the Web’s Leading Search Engines are Really Looking For” – by Keith Boswell
Google’s database contains over 2 billion documents. Estimates suggest Google reviews anywhere from 8 to 10 billion documents to create their index. Danny Sullivan from SearchEngineWatch.com refers to the pages that are not included in a search engine index as the “invisible web”.
How do you go from being a part of the “invisible web” to the part readily found by people searching at Google and other popular search destinations? Often people are misguided into thinking the best way to show up in Google is to find as many websites as possible to provide a link back to their website. Many people know PageRank, Google’s proprietary method for ranking a page, looks at links to help determine a page’s relevancy.
Here is what Google says about PageRank at their website:
“PageRank relies on the uniquely democratic nature of the web by using its vast link structure as an indicator of an individual page’s value. In essence, Google interprets a link from page A to page B as a vote, by page A, for page B. But, Google looks at more than the sheer volume of votes, or links a page receives; it also analyzes the page that casts the vote. Votes cast by pages that are themselves “important” weigh more heavily and help to make other pages “important.”
This seems to be where most people stop. They don’t go on to read the next section of the description which is an even more important disclosure about what Google is really looking for – quality content.
“Important, high-quality sites receive a higher PageRank, which Google remembers each time it conducts a search. Of course, important pages mean nothing to you if they don’t match your query. So, Google combines PageRank with sophisticated text-matching techniques to find pages that are both important and relevant to your search. Google goes far beyond the number of times a term appears on a page and examines all aspects of the page’s content (and the content of the pages linking to it) to determine if it’s a good match for your query.”
Google uses PageRank as one factor in determining if a site is relevant to a search request. A more important factor to them than PageRank is the content of a given page and the content on the pages that link to it. You could establish one million links to your website, but if they have no relevancy or content related to a search request, they don’t mean anything to Google. This is also true for the other crawler based search engines Inktomi and FAST as they all face the same challenge.
Many are quick to quip, “Who is Google to determine relevancy? The products and services I offer are the best in my market space? I should show up Number #1 for a search without question.” That may be true in the offline world, but online does your website accurately reflect and describe your products and market space enough to establish your perceived leadership?
Google and Inktomi have created search engines known for delivering quality results: successfully matching a person with a website they are looking for. These engines strive for relevancy. This means that a website must prove, through the content and structure of its code, that it is pertinent to a search request.
There seems to be a great misunderstanding that products and services alone build a successful web business. The web was created as a way to share information. Search engines were a by-product of that movement as Internet users looked for ways to find the information they believed was out there.
Because we have not created a governing method of identifying data online, like the Dewey Decimal system for books, search engines can only hope to find highly relevant documents containing text similar to the keyword terms people are searching for. To do this, they have to review the content of a website and evaluate the people who are linking to it.
Looking at part of the equation, if a website only gives an end user product numbers, images, five word descriptions, and a shopping cart, that website is less relevant than a website that accurately describes the products it carries, provides useful images of those products, and publishes editorials and consumer resources valuable to that market.
The onus does not fall on Google, Inktomi, FAST or the rest of the Web to find your website relevant. The responsibility lies with your online business to create something worthy of being included in these search engines databases and linked to by other websites. You have to contribute relevant content to your market space if you want to be found and reflected in search engines.
The more valuable content you create and share about your online business, the more credibility you are establishing. This also usually means that others will start to find your website and link to it because of the value your website provides. This hopefully helps to contribute to increasing the quality of your content and your relevance in the major search engines.
Showing up in Google should be much easier if you continually focus on your websites content. Be creative and show the same leadership online that you do offline. Contribute to your market and your market will give back to you.
In an age where the Web is quickly becoming a part of all businesses, remember why the Web was created – to share information with everyone who’s connected. Search engines are just trying to make sense of it all as a benefit to the public. If search engines can’t tell your website has something to do with your market, your potential customers are feeling the same way.
|
|
|
6/20/03 – Google-Dance is over!
|
|
|